Intelligence DispatchesJune 12, 20266 min read
From Latest X Tweets to Blog Gold: How I Aggregate 'Best of X' Into Reference Pieces
The exact process I use to turn real-time X signals (keyword + semantic searches, high-engagement threads, creator workflows) into evergreen, embed-rich, updateable blog posts that drive authority, AEO, and distribution.
Reading Goal
You will have a repeatable, documented process to harvest timely X signals, synthesize them into a high-signal reference post with live embeds, generate supporting visuals, gate for quality, and distribute for maximum compounding value.
TL;DR — X is the fastest primary source for what is actually working right now in AI tools, creator workflows, and monetization experiments. The blog post that lasts is the one that treats those signals as primary source material, quotes the real posts with live embeds, adds synthesis and FrankX production reality, and ships with proper schema + internal links so it stays referenceable and updateable.
This is the full overnight-to-publish workflow I used for the June 2026 AI video generators dispatch (and the companions).
Why X-First Research Wins for This Category
The frontier moves in weeks. A traditional "best of 2026" article written from vendor sites and review roundups is already stale by the time it ranks.
X (especially high-engagement threads from creators who actually ship) shows:
- What just dropped and how people are using it in production (MCP + Claude examples, agentic "supercomputer" workflows).
- Real pricing and access friction (business email verification, credit math complaints, self-hosted rebuild celebrations).
- Which monetization paths people are actually talking about (Higgsfield Earn performance payouts vs traditional affiliate application delays).
- The slop warnings that only appear when someone posts the cheap-looking result next to the premium one.
The posts with real engagement (thousands of likes, millions of views on official drops, hundreds on workflow case studies) are the ones creators are saving and sharing internally. Those are the primary sources.
The Harvest Phase (Tools + Filters)
I run parallel searches with clear scope:
- Keyword searches on the tool names + "min_faves:5 since:2026-01-01" (or tighter recency) in Top mode for the loudest signals.
- Semantic searches on the broader question ("best AI video generators tools 2026 higgsfield sandcastles reviews recommendations") limited to 2026.
- Thread fetches on the highest-engagement post IDs that surface, to get the full context and quote accurately.
- Web cross-check for official pricing, affiliate pages, and recent reviews to ground the X anecdotes.
Specific post IDs I pulled for the video piece (all public, high-signal):
- 2039535191098802315 — Higgsfield Seedance 2.0 official (millions of views)
- 2063253603226157460 — Real-business MCP + Claude use case
- 2054808204950016377 — Agentic "supercomputer" layer
- 2014699047517651116 — Influencer studio + monetization campaign
- 2042143574394073595 — Open-source self-hosted rebuild reaction
- 2016132038265614703 — Practical tools + pricing + services reality list
For the Sandcastles companion I also pulled the direct mention of the Claude plugin analyzing short-form performance (2064004295427551453) plus the broader pattern of "scan outliers → write script" posts that get strong engagement.
I store the raw post text + engagement numbers + direct links. No summarization until the synthesis pass.
The Synthesis Pass (Thesis First)
Before writing a single section, I force the thesis from the brand's own gen layer language:
"The product is not any single model. It is the curated menu + the taste lanes + the gate + the learning loop."
Everything else serves that. The X posts become evidence for the menu (Higgsfield as access layer), the lanes (cinematic vs volume vs control), the gate (storytelling + editing separates premium from slop), and the loop (log what won, update the next brief).
Only after the thesis is locked do I outline sections:
- Aggregated top signals (with real embeds + engagement context)
- Head-to-head table (synthesized, not invented)
- Affiliate/monetization reality (what people are actually saying pays)
- FrankX/ACOS workflow recs (hybrid native + premium + research layer)
- Right tool for use case + backups
- FAQ (for schema)
This keeps the piece from becoming a link list and turns it into a durable reference.
Rich Embeds & Visuals (The Authority Layer)
Live X embeds are the single highest-ROI addition for this type of post.
In this codebase we use the exported TwitterEmbed (or full UniversalEmbed type="twitter") from components/embeds/UniversalEmbed.tsx. It renders the official Twitter embed iframe with a tasteful dark header bar, external link, and lazy-load click-to-play behavior.
In MDX I drop them inline with title for context:
<TwitterEmbed id="2039535191098802315" title="Higgsfield Seedance 2.0 official launch — millions of views" />
They deliver:
- Social proof (the actual post the creator community saw)
- Freshness (embeds update if the original post gets more engagement)
- Click-through to X for distribution flywheel
- AEO/SEO value (quoted primary source + structured context)
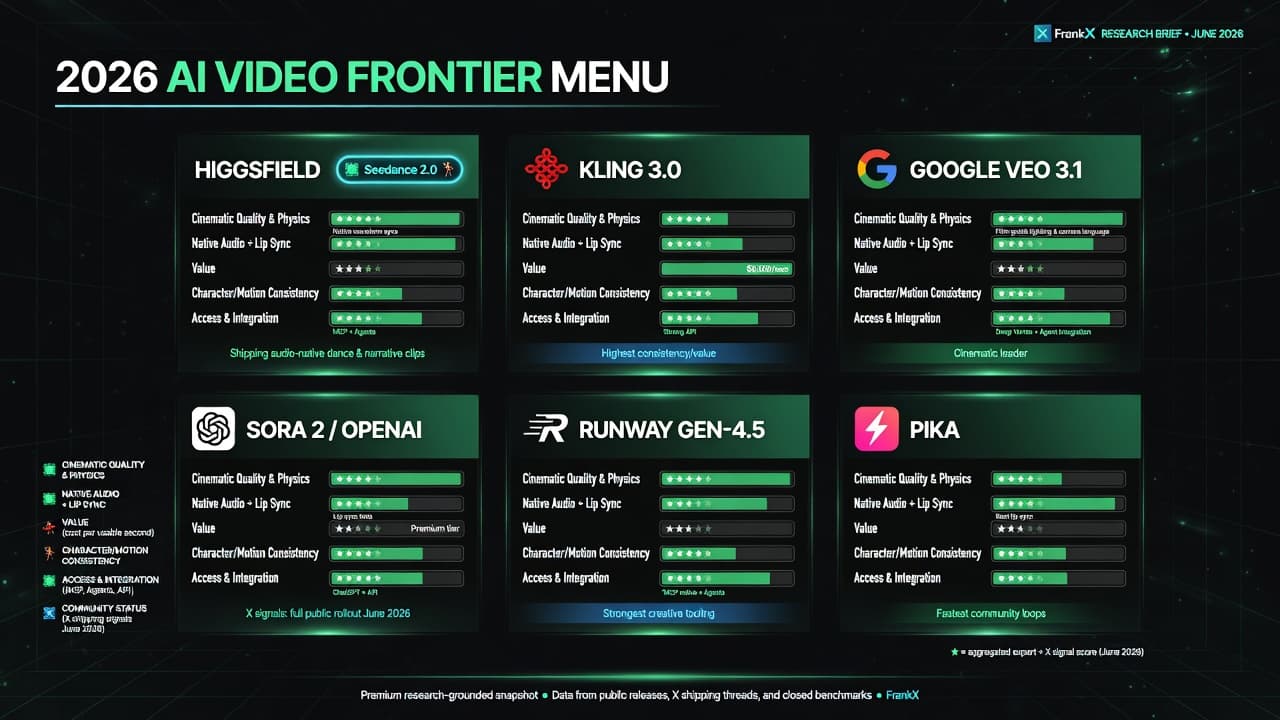
For visuals I generate two assets via the available image engine (infogenius/research-grounded lane for the comparison "menu", clean table for the head-to-head):
- Hero: "2026 AI Video Frontier Menu" comparison (wide 16:9)
- Inline: Structured head-to-head table image (4:3 or square)
Paths go under /images/blog/. I keep the generation prompt and lane note in the post so future updates can regenerate in the same style without drift.
Annotated "screenshots" of key results are described or generated as supporting stills when a specific output example adds clarity.
Writing, Internal Links, Schema, Gate
Frontmatter follows the strict blog schema (category "Intelligence Dispatches", 3-5 tags, readingGoal, schema: ["Article", "FAQPage"]).
Internal links are deliberate and bidirectional where possible:
- /studio/engines (the menu in production)
- /blog/ultimate-higgsfield-workflow-2026 (recent detailed setup)
- /blog/best-ai-image-generators-2026 (parallel image piece)
- Research hub and visual-intelligence posts
FAQ at the end satisfies the FAQPage schema and answers the real objections that appear in the X threads.
Gate (before any publish or staging move):
- Run the full restraint + no-slop checklist from taste.md (no "delve", "revolutionary", "it's worth noting", etc.).
- Read every X quote in context to avoid misrepresentation.
- Verify every number or claim against the original post or web source.
- Check 3+ strong internal links.
- Title ≤60 chars, description ≤160.
- Hero image exists and matches the lane.
Only then does it move to content/blog/ (or staging/ per current ops).
Distribution & Compounding
- Immediate X thread that quotes the key embedded posts + links the full piece (drives both blog traffic and X engagement on the source posts).
- Tease in the next newsletter / research dispatch.
- Reference in /newsletter-week or /traffic-week planning when the topic fits the cadence.
- Amplify on LinkedIn/Threads with the same embeds or static quote cards.
- Future posts link back to this one as the "June 2026 X snapshot."
The embeds + primary-source quotes make the post naturally referenceable. Future "best of" pieces or research hub entries can cite it instead of re-aggregating from scratch.
The Meta Meta (Why This Process Exists)
The real product is not the blog post. It is the operating loop:
Harvest real-time primary signals (X is currently the best raw feed for tool adoption and friction) → Synthesize against durable brand thesis (menu + taste + gate + learning) → Package with embeds + visuals + schema so it compounds → Distribute through the same channels that produced the signals → Log what performed → Update the next harvest.
Do this consistently and the blog stops being "content" and becomes infrastructure — the reference layer that makes every future piece stronger and every distribution cycle more efficient.
This post is the operating manual for that infrastructure.
Companion to the June 2026 AI video generators X-aggregated dispatch and the research-generation flywheel piece. The process is reusable across any fast-moving tool category.
Get Started
Build your first AI system
Step-by-step guide to setting up ACOS, creating your first agent, and shipping real products with AI.
Start buildingTemplates & Blueprints
Production-ready architecture
Download AI architecture templates, multi-agent blueprints, and prompt engineering patterns.
Browse templatesInner Circle
Join the builder community
Connect with creators and architects shipping AI products. Weekly office hours, shared resources, direct access.
Join the circleFrankX.AI / AI Architecture, Creator Systems, and Builder Intelligence
Stay in the intelligence loop
Weekly field notes on AI systems, production patterns, and builder strategy.
Continue Reading
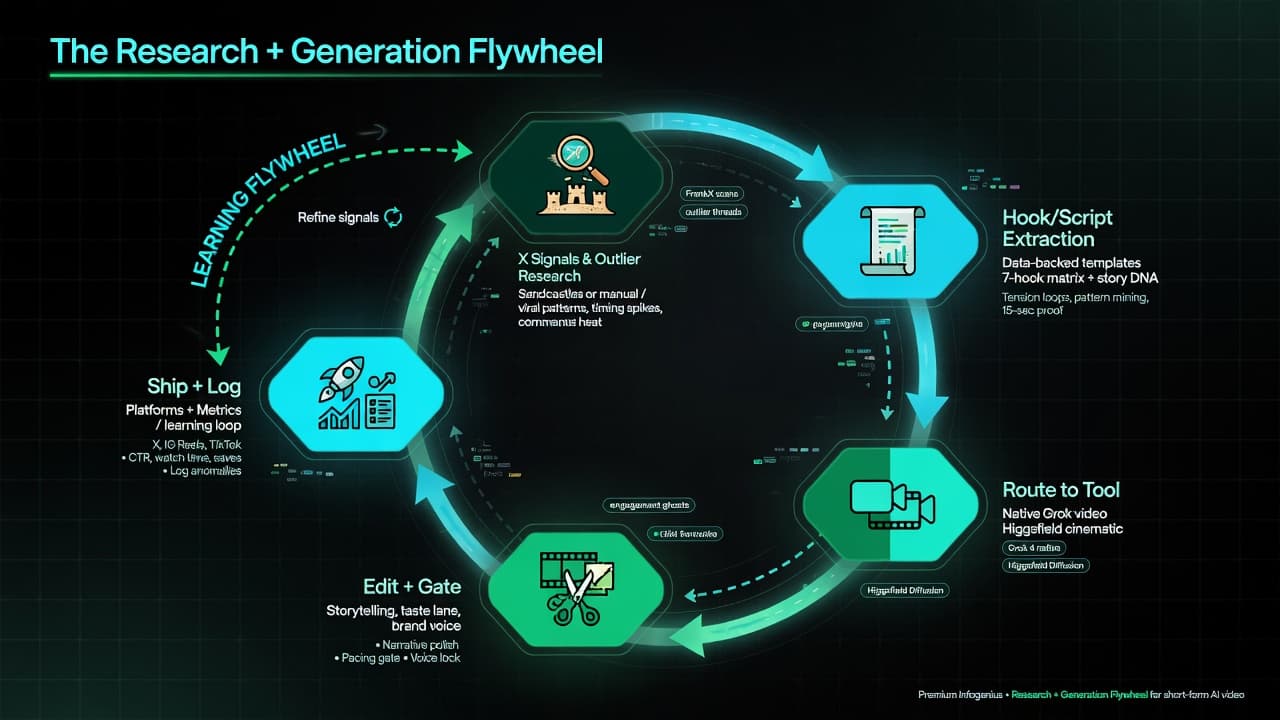
Intelligence Dispatches6 min read
The Research + Generation Flywheel: Sandcastles-Style Analysis + Higgsfield/Grok Execution
How data-backed short-form research (Sandcastles or X outlier signals) feeds directly into production (Higgsfield, native Grok video tools, editing). The exact weekend workflow that turns signals into shipped shorts, hooks, and reference content.
Read article
Intelligence Dispatches12 min read
How to Get Cited by ChatGPT and Perplexity: The AEO Playbook for 2026
Answer Engine Optimization is how you become the source AI quotes. The on-page and off-page playbook to get cited by ChatGPT, Perplexity, and Gemini — with a checklist and the tools that track it.
Read article
Workshops12 min
The Creator's AI Toolkit: Build Your Complete Content System
Transform from overwhelmed creator to AI-empowered content machine. Build ideation engines, research pipelines, writing assistants, and distribution automation.
Read article